Armv8-高速缓存基础
高速缓存基础知识
高速缓存用来解决处理器访问速度和内存访问速度严重不匹配的问题。高速缓存英文名为cache,由若干个cache line(缓存行)组成。一个缓存行通常可包含64个字节的数据,同时标志信息有:有效位、标记地址(用于标识其对应的物理地址)。cache以缓存行为单位和内存进行数据读取和写回。
处理器在查找cache时,会将地址分割为如下形式:

高速缓存,是由n个路组成的。例如32KB大小的4路组相联高速缓存中,就有4个路,每路大小为32/4=8KB。如果cache line的大小为32B,则一路包含8KB/32B=256个cache line。这些cache line的寻址则是通过索引域,此例中256个cache line则需要8位的索引域。
索引域相同的多路cache line可以看成一个组。当通过索引域索引到一组cache line后,通过比对各个cache line的标记域(tag),如果能找到对应的cache line,则命中,之后根据偏移量即可获得数据;否则,则需要访存。
这样,如果索引域相同、但并不相等的多个地址,其数据则会缓存到同组上的不同路。因此cache在查找时,则会并行地根据索引域对所有路进行cache line的查找,并进行标记域的比对。
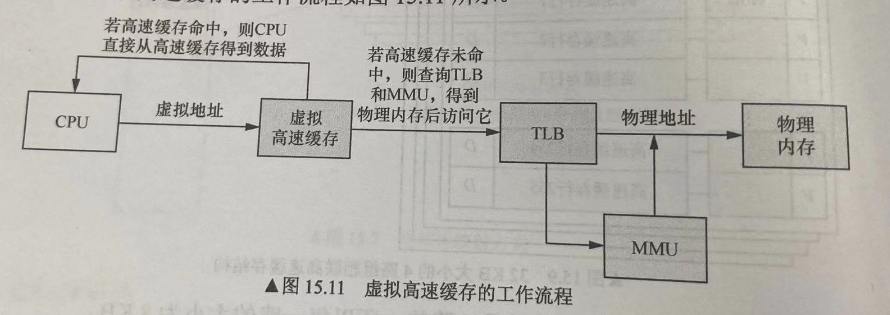
高速缓存根据是通过物理地址还是虚拟地址寻址,可以分为物理高速缓存和虚拟高速缓存:

但由于寻址是利用了索引域和标记域2个坐标,因此还可以细分为3种高速缓存:
- VIVT(Virtual Index Virtual Tag):使用虚拟地址的索引域和标记域。
- PIPT:使用物理地址的索引域和标记域
- VIPT:使用虚拟地址的索引域和标记域。这种做法好处有:修改虚拟地址和物理地址映射关系后,不需要invalidate 对应的cache line;当索引域位于页内偏移区域时,不会产生重名问题。
使用虚拟高速缓存时,可能会出现2种问题:
- 重名:多个不同的虚拟地址映射到同一个物理地址,导致修改一个虚拟地址数据时,可能会导致同一物理地址的缓存数据不一致。
- 同名:同一个虚拟地址映射到不同的物理地址,例如进程切换时如果不进行一些机制的处理,则可能出现这种问题。
高速缓存的策略
当处理器要执行读写内存操作时,这些操作首先会查询cache,然后根据cache设定的不同策略进行以下判断和决策。
写内存
如果写命中,则有策略:
- 直写:数据同时写入当前和下一级cache line以及主存
- 回写:数据只写入当前高速缓存,只有当该cache line被替换时,才会更新到下一级cache line或主存
如果写未命中,则有策略:
- 写分配:分配一个新的cache line并写入数据
- 不写分配:不分配cache line,直接写入内存
读内存
如果读命中,则直接从cache获取数据;如果读未命中,则有策略:
- 读分配:先将数据加载到cache,再从中获取数据
- 读直通:不经过cache,直接从内存读
维护高速缓存
cache缓存的是内存里的数据,而内存中的数据能被cache缓存的前提是该内存区域是可缓存的普通内存。进一步地,我们还可以指定这个内存区域是内部共享的还是外部共享的,如果是内存共享的,则可以缓存在处理器核内部的cache,如L1 cache;如果是外部共享的,则只能缓存在通过系统总线扩展的高速缓存,可能是L3 cache。
对高速缓存的管理分为3种情况:
- 失效:使cache失效,丢弃其数据
- 清理:将某个cache line写回到内存或下一级高速缓存。
- 清零
通过指令DC、IC可以分别对数据高速缓存和指令高速缓存进行管理。其格式为:
DC <operation>, <Xt>
IC <operation>, <Xt>
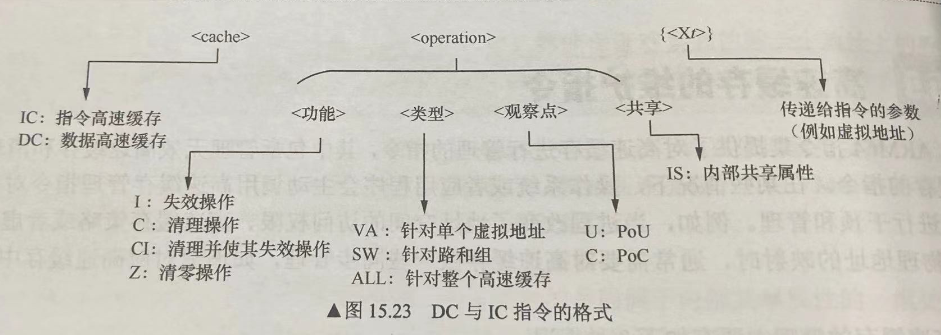
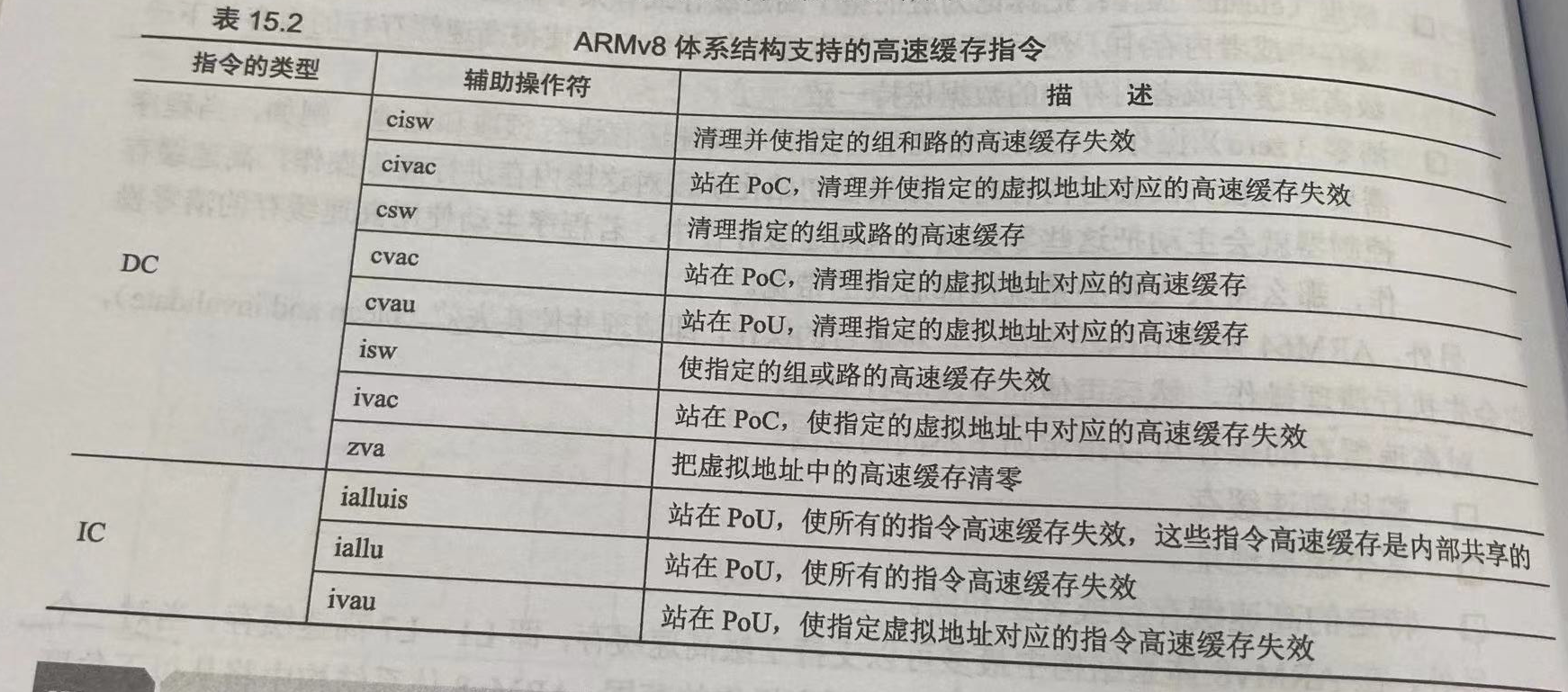
这里的PoC和PoU规定了高速缓存维护指令作用的范围。对于PoC,则表示全系统(包括所有处理器、DMA、GPU)都会看到这个指令执行后的效果。而PoU则只限于内部共享域的处理器会看到指令作用的效果。
查看高速缓存的信息
CLIDR_EL1寄存器:通过Ctype<n>字段标识系统最高支持几级高速缓存,通过ICB字段标识最高级别的内部共享的高速缓存是第几级。
CTR_EL0寄存器:IminLine和DminLine分别表示指令高速缓存和数据(以及联合)高速缓存的cache line大小;L1Ip表示L1指令高速缓存的策略,例如虚拟索引物理标记等。
CSSELR_EL1和CSSIDR_EL1寄存器:通过指定CSSELR_EL1寄存器中要查询的cache层级、类型,可以通过CSSIDR_EL1得到对应cache的路、组数量。