站在OS使用者的角度理解体系结构
本文的主要意图, 是进行操作系统编程时遇到的有关内存维护, 并发问题的总结.
缓存一致性
缓存一致性关注的是同一数据在多个高速缓存和内存中的一致性问题. 这个是由MESI协议由硬件自动维护的.
内存屏障指令
寄存器依赖性: 一个指令用到了前面的指令所写入的寄存器. 这样这条指令必须被排在前面指令之后执行. 例如
LDR x0, [x1]
LDR x2, [x0, #4]
地址依赖性: 多个指令依次写重叠的一段地址, 无论怎样重排序必须保证最终效果是一致的. 例如
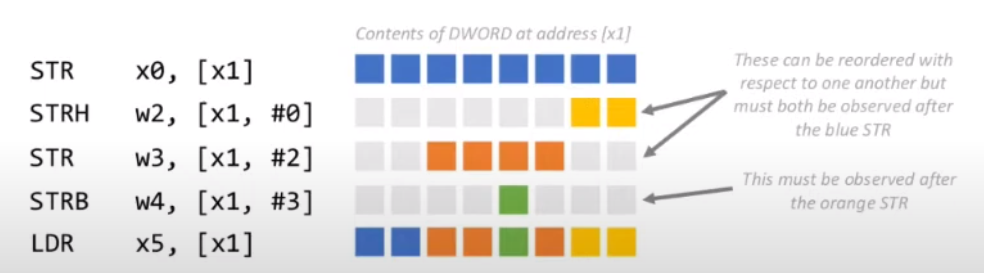
如果对内存操作的指令之间不存在这两种依赖性, 那么对于ARM来说, CPU可能就会进行重排序. 这就是ARM的弱一致性模型.
- 什么情况下需要考虑使用Barrier
当多个线程(注意, 一个CPU多个线程也需要)共享同一个数据时
当多个观察者(外设和内存)共享同一个数据时
改变本地CPU的配置(系统寄存器, 虚拟内存布局)
这3种情况下,如果一个CPU访问内存的顺序会对系统中其他观察者造成影响时,则需要使用内存屏障指令来保证其他观察者观察到正确的访问序列。
3种内存屏障指令
DMB
数据存储屏障Data Memory Barrier,DMB:在dmb指令之前的所有内存访问指令都执行完,才会执行dmb指令之后的内存访问指令。需要注意的有2点:
- 只对内存访问指令有影响,如load, store,还有数据高速缓存、TLB维护指令。注意,IC不是内存访问指令。
- 保证的是访问的次序,不保证内存访问指令在dmb之前完成。
DSB
数据同步屏障Data Synchronization Barrier, DSB:比DMB严格,只有它前面的内存访问指令以及高速缓存,TLB维护指令都执行完后,才会执行它后面的指令。
另外在多核系统中,高速缓存和TLB维护指令会广播到其他CPU,DSB会等待这些CPU发回应答信号,表示它们也观察到了这些维护指令的效果,DSB指令才算执行完。因此,在使用DC、IC或TLBI等维护指令时,常伴随着DSB指令。DMB指令则不会等待应答信号
- DMB和DSB指令的参数
这两个指令后面都可以加参数,参数规定了作用域,作用方向。

例如对于SY,访问顺序为内存读写指令,表示在内存屏障指令之前的所有读写指令必须在内存屏障指令之前执行完;共享属性为全系统共享域,则表示该内存屏障指令的可见范围为整个系统可见,例如当两个CPU簇之间(Cortex-A和Cortex-M)共享数据时,Cortex-A的CPU执行dmb sy指令,Cortex-M的CPU就会看到这个指令执行的效果,否则则不会看到。
这里的"看到"是从观察者角度考虑的问题,执行这些指令,有时就会影响其他观察者,共享属性就是指定了会影响的观察者的范围。
ISB
指令同步指令(Instruction Synchronization Barrier, ISB): 执行ISB指令会冲刷流水线,确保所有在ISB指令之后的指令都从指令高速缓存或内存中重新预取。通常在执行ic指令后,需要执行isb指令。
注意,这3种内存屏障指令的执行是顺序的,不会乱序执行。
高速缓存维护指令与内存屏障指令
使用IC/DC等cache维护指令时,通常需要配合内存屏障指令。例如:
- 使用IC和TLB维护指令后一般要跟一个DSB指令,确保指定共享域中所有的CPU内核都可以看到并执行。
- 如果想保证DC和其他指令的执行顺序,最好加DSB或DMB,否则可能会乱序执行。但是当存储和加载指令访问的地址与DC访问的地址在同一个高速缓存行时,CPU保证不会乱序
实现自旋锁
自旋锁的原理:当lock为0时,表示锁是空闲的;当lock为1时,表示锁已经被CPU占有。
存储缓冲区与写内存屏障指令
由于缓存一致性的存在,当多个CPU共享一些数据时,会导致总线带宽被缓存一致性的广播信号大量占用,而被迫等待的CPU则浪费大量时间。因此出现了存储缓冲区,位于CPU和L1高速缓存之间,当需要写数据时,可以先写入存储缓冲区,等到收到其他CPU的应答信号后,再写入cache line中。而当需要读数据时, 如果存储缓冲区中有该数据的副本,则会从存储缓冲区中读取数据,这个功能被称为存储转发。
然而由于存储缓冲区的存在,当多个CPU共享的数据在代码之间有依赖性时,不加内存屏障指令可能出现问题。CPU0的数据被写入到了存储缓冲区中,并向CPU1发出了总线写信号。然而CPU1之后读该数据时,还未收到总线写信号,因此读到的数据是旧数据,导致错误。
解决办法是在CPU0的两个数据写的位置之间加入dmb ishst指令,该指令会给此时在存储缓冲区中的数据做个标记,之后要写的数据必须得等这些已标记的数据写入到cache line中,才会写入cache line,一旦写入cache line,就表示已经完成缓存一致性所规定的内容了,其他CPU可见数据了
无效队列与读内存屏障指令
由于存储缓冲区的表项数量有限制,故有时CPU还是会陷入停滞。为了防止让存储缓冲区的表项数量过多,直接的办法就是缩短CPU发出总线读写信号到收到应答信号的时间。因此CPU设计者们在高速缓存和总线之间增加了一个无效队列的硬件单元,当CPU收到了要使cache line失效的总线请求后,会将该请求加入无效队列中,并立刻回复一个应答信号,无需当CPU完成cache line的失效操作后才发出应答信号,缩短了接收应答信号的时间。
然而,如果无效队列中的请求还未上交给cache,那么CPU如果读取该数据,则还是会读到旧数据。(写的话没事,因为会等待无效队列中该cache line先失效后才会执行后面有关总线的操作)因此可以通过读内存屏障指令dmb ishld,该指令会标记当前无效队列中的所有请求,只有当这些请求都失效后,才会执行后面的读指令。
问题
- [x] TLB每个表项的结构
TLB是MMU中的一个硬件单元,不在内存里。其表项包含多个域,其中最重要的是VPN,PPN,ASID,分别为虚拟地址页帧号,物理地址页帧号,进程地址空间ID
- [x] cache存储的内容
cache中一个表项就存储着这个地址对应的数据